#
source("funciones_extraerfotos.R")
func_extraer_fotos(ficheropdf = "Ficha.pdf",
raiz_nombrefotos = "fotoAsig") He comenzado a usar la aplicación IDOCEO en mi iPad para mantener actualizada toda la información relacionada con los alumnos a los que les doy clase en las distintas asignaturas que imparto en el Departamento de Estadística e Investigación Operativa de la Universidad de Sevilla.
Una de las primeras cuestiones que quería conseguir es tener un listado de todos mis alumnos con su foto. La Universidad de Sevilla dispone de un servicio web con la Secretaría Virtual (“Sevius”). Una de las opciones disponibles para los profesores es la de obtener un listado completo de los alumnos de clase, eligiendo las siguientes opciones:
Datos como docente -> Listas de Clase -> Seleccionar Grupo
Hay disponibles varios formatos:
- HTML,
- Texto,
- Formato compatible Excel,
- Formato PDF (adobe acrotab).
Se debe:
- seleccionar “Formato HTML”,
- pulsar el botón “Obtener lista de clase”.
- Y a continuación, pulsar el botón “Obtener ficha de todos los alumnos”.
Se descargará un fichero pdf de varias páginas: “Ficha.pdf”:

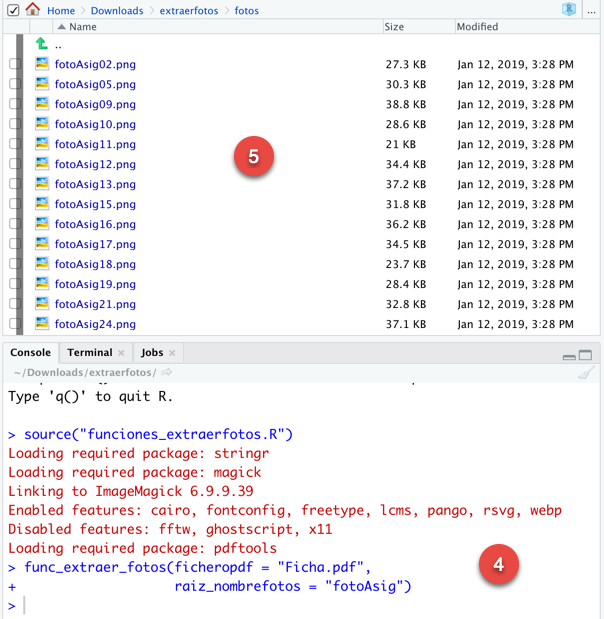
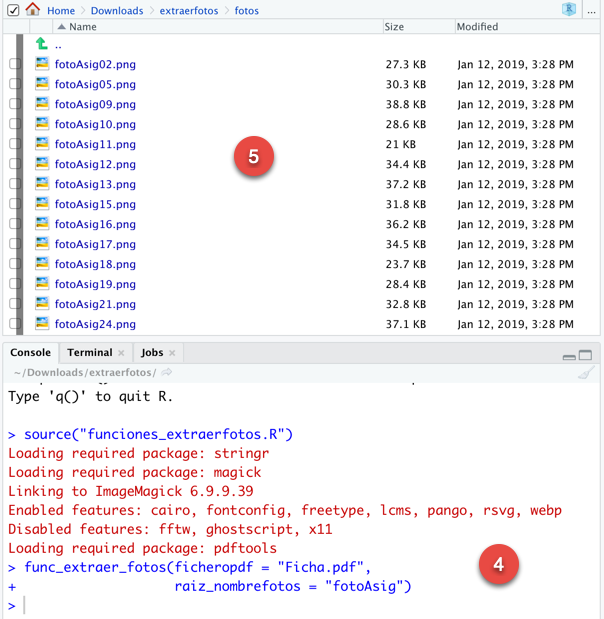
En cada página aparecen los datos de dos alumnos o dos fichas. Junto a la información de cada alumno, suelen aparecer dos gráficos: uno con el escudo de la Universidad de Sevilla y otro con la foto del alumno, si está disponible.
El objetivo es extraer todas las fotos de alumno existentes en el fichero pdf: “Ficha.pdf”.
Instalación del software libre necesario: R, RStudio y Xpdf tools
Para ello se utilizará varios programas de software libre, disponibles para los sistemas operativos más habituales: Windows, Linux y Mac:
- R (vídeo de instalación de R en Windows)
- RStudio (vídeo de instalación de RStudio en Windows)
- Xpdf tools. Nota: descomprimir los ficheros en la misma carpeta del proyecto que contiene el código R.
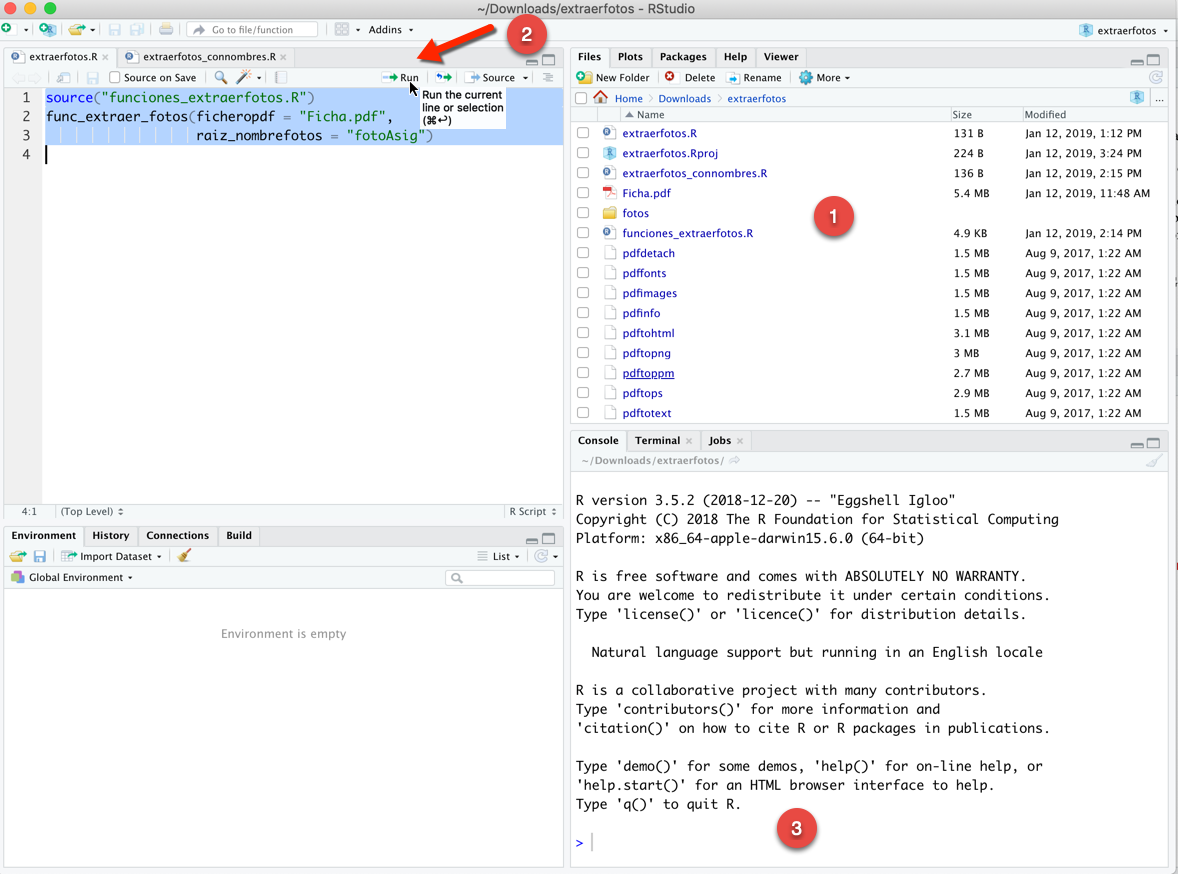
Una vez instalado en nuestro ordenador este software, y con el código R que se ha desarrollado (ver último apartado), tan solo se tendrían que ejecutar las siguientes instrucciones (código incluido en el fichero “extraerfotos.R”):
Nota
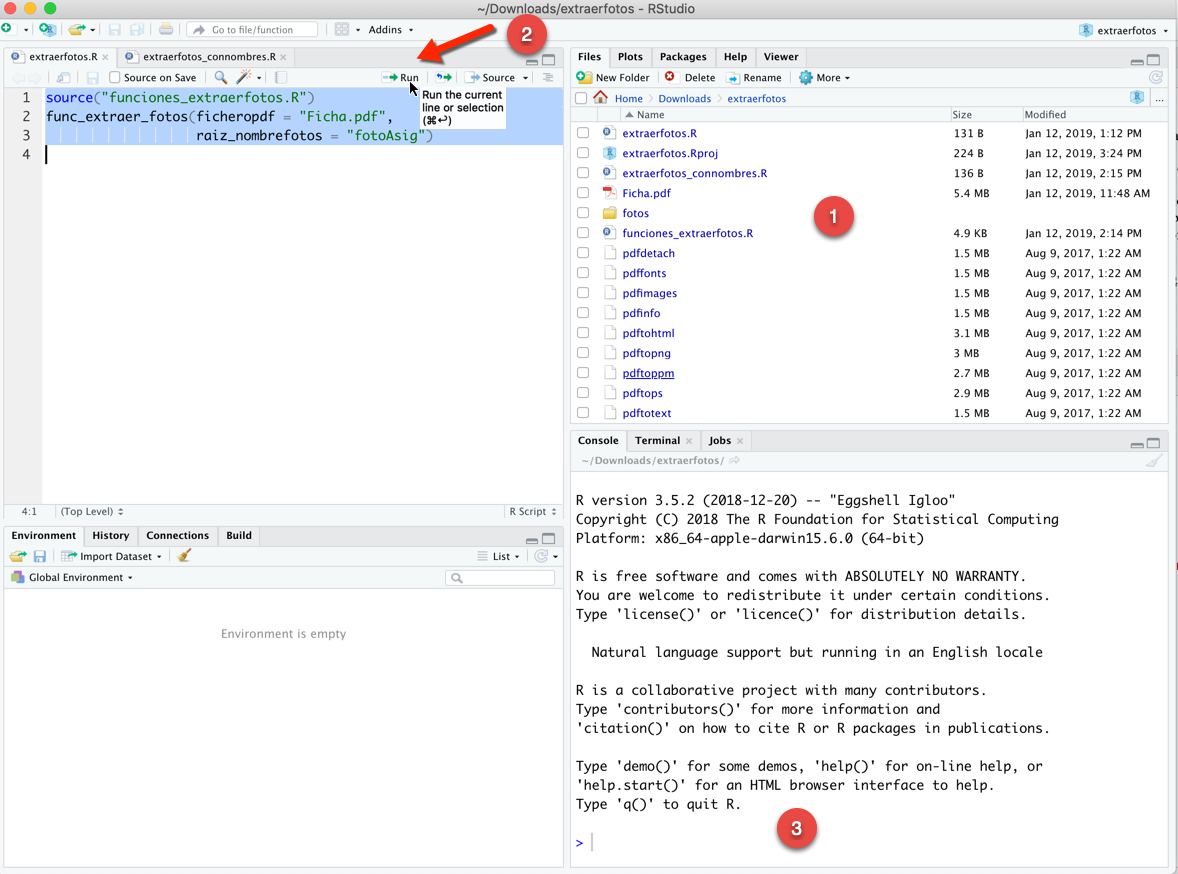
Nota. Para descargar la información textual, lo más adecuado es bajarse el listado de clase pero en un fichero con formato compatible Excel, el cual podrá utilizarse en la aplicación IDOCEO para crear el listado de alumnos para una asignatura. Este proceso debería hacerse en IDOCEO previamente a subir las fotos. El Prof. Óscar Requena ha creado un vídeo en youtube (sesión 1/8) que explica las distintas formas de importar los listados de alumnos en IDOCEO.
Descripción del código R utilizado para extraer imágenes
En el fichero “funciones_extraerfotos.R” está incluida la definición de la función R: func_extraer_fotos, que nos permite realizar todo el proceso de extracción de fotos, con ayuda de las librerías de R: magick y stringr.
A continuación se recoge el código R que define la función, en la que se han incluido comentarios que explican la tarea que se está llevando a cabo:
# Carga las librerías R necesarias y si no están instaladas las instala
if (!require(stringr)) {
install.packages("stringr")
library(stringr)
}
if (!require(magick)) {
install.packages("magick")
library(magick)
}
# La definición de la función: func_extraer_fotos()
# tiene dos argumentos opcionales:
# - ficheropdf: nombre del fichero que contiene los datos alumnos
# - raiz_nombrefotos: raíz del nombre que llevarán todas las fotos
func_extraer_fotos = function(ficheropdf = "Ficha.pdf",
raiz_nombrefotos = "foto") {
# Paso 1: llama al programa "pdfimages" para extraer las imágenes
comando = paste0("./pdfimages -list ",ficheropdf," ",
raiz_nombrefotos," > salida.txt")
# En Windows, descomentar la siguiente orden
#comando = paste0("pdfimages.exe -list ",ficheropdf," ",
# raiz_nombrefotos," > salida.txt")
system(comando)
# Paso 2: extrae los nombres de los ficheros que contienen las imágenes
# y detecta cuáles son escudos
salida = readLines("salida.txt")
# escudo en líneas con las siguientes características
# foto-0000.ppm: page=1 width=150 height=150 hdpi=120.00 vdpi=120.00
donde_escudo = str_detect(salida,"width=150")
cuales_escudo = which(donde_escudo)
nombres = str_split(salida,": ")
vnombres = c()
for (i in 1:length(salida)) {
if ((i %in% cuales_escudo)) {
vvnombre = nombres[[i]][1]
unlink(vvnombre)
} else {
vnombres = c(vnombres,nombres[[i]][1])
}
}
# Paso 2b: detecta fotos faltantes: N
ffal = c("E")
for (i in 2:length(donde_escudo)) {
img_ant = donde_escudo[i-1]
img_act = donde_escudo[i]
if (img_act) { # actual escudo: E
if (img_ant) { # anterior escudo: E
ffal = c(ffal,"N","E") # dos escudos seguidos: falta foto
} else { # anterior foto:
ffal = c(ffal,"E") # foto y escudo: escudo
}
} else { # actual foto: F
if (img_ant) { # anterior escudo: E
ffal = c(ffal,"F") # escudo y foto: sí hay foto
} else { # anterior foto:
ffal = c(ffal,"E","F") # foto y foto: falta escudo
}
}
}
ifotos = which(!(ffal=="E"))
qfotos = ffal[ifotos]
sifotos = which(qfotos=="F")
# Crea el subdirectorio "fotos" si no existiera, para guardar fotos encontradas
if (!dir.exists("fotos")) {
dir.create("fotos")
}
# Paso 3: borra los escudos y guarda las fotos en formato png
# colocando el número del alumno con foto en el orden del listado
cadenafmt = paste0("fotos/",raiz_nombrefotos,"%02d.png") # "fotos/foto%02d.png"
#vsnombres = sprintf(cadenafmt,1:length(vnombres))
vsnombres = sprintf(cadenafmt,sifotos)
for (i in 1:length(vnombres)) {
fichero = image_read(vnombres[i])
fichero_png = image_convert(fichero,"png")
image_info(fichero_png)
image_write(fichero_png,path = vsnombres[i])
unlink(vnombres[i])
}
}Descripción del código R utilizado para extraer imágenes y texto
En las fichas de alumnos también aparece información textual:
- Apellidos, nombre
- NºDocumento
- Correo electrónico
- Teléfono curso
- Teléfono familiar
- Fecha nacimiento
- Uvus
que podría extraerse para algún uso adicional.
Para extraer las fotos disponibles en el fichero “Ficha.pdf” con nombres de ficheros que contienen los apellidos+nombre de los alumnos que sí tienen su foto, tan solo se tendría que ejecutar el siguiente código desde RStudio (código incluido en el fichero “extraerfotos_connombres.R”):
Nota
#
source("funciones_extraerfotos.R")
func_extraer_fotos_mej(ficheropdf = "Ficha.pdf",
raiz_nombrefotos = "nfotoAsig") {{% figure src="./rstudiofotos03.png" title="Esta captura muestra la ejecución de la funciónfunc_extraer_fotos_mej()para extraer las fotos con los nombres de los alumnos." numbered="true" %}}
La principal diferencia ha sido incorporar en esta función el siguiente código R, que con ayuda de la librería R: “pdftools”, y su función pdf_text permite extraer el texto incluido en un fichero pdf.
# Paso 2c: extrae apellidos y nombre de los alumnos
text <- pdf_text(ficheropdf) # extrae el texto de todas las páginas del pdf
dat01 = c() # contiene apellidos y nombre
dat02 = c() # contiene apellidos y nombre separados por guiones
for (j in 1:length(text)) { # trabaja con el texto de cada página
pagina = str_split(text[j],"\n")
lineas = unlist(pagina)
for (i in 1:length(lineas)) {
res = str_detect(lineas[i],"Apellidos, nombre") # busca dónde aparece Ape
if (res) {
ss = unlist(str_split(lineas[i],"Apellidos, nombre"))
ss1 = str_trim(ss[2])
dat01 = c(dat01,ss1)
dat02 = c(dat02,str_remove_all(str_replace_all(ss1," ","_"),","))
}
}
}A continuación, se recoge el código R completo con la definición de la función: func_extraer_fotos_mej():
if (!require(pdftools)) {
install.packages("pdftools")
library(pdftools)
}
func_extraer_fotos_mej = function(ficheropdf = "Ficha.pdf",
raiz_nombrefotos = "foto") {
# Paso 1:
comando = paste0("./pdfimages -list ",ficheropdf," ",
raiz_nombrefotos," > salida.txt")
# En Windows, descomentar la siguiente orden
#comando = paste0("pdfimages.exe -list ",ficheropdf," ",
# raiz_nombrefotos," > salida.txt")
system(comando)
# Paso 2:
salida = readLines("salida.txt")
# escudo en líneas con las siguientes características
# foto-0000.ppm: page=1 width=150 height=150 hdpi=120.00 vdpi=120.00
donde_escudo = str_detect(salida,"width=150")
cuales_escudo = which(donde_escudo)
nombres = str_split(salida,": ")
vnombres = c()
for (i in 1:length(salida)) {
if ((i %in% cuales_escudo)) {
vvnombre = nombres[[i]][1]
unlink(vvnombre)
} else {
vnombres = c(vnombres,nombres[[i]][1])
}
}
# Paso 2b: detecta fotos faltantes: N
ffal = c("E")
for (i in 2:length(donde_escudo)) {
img_ant = donde_escudo[i-1]
img_act = donde_escudo[i]
if (img_act) { # actual escudo: E
if (img_ant) { # anterior escudo: E
ffal = c(ffal,"N","E") # dos escudos seguidos: falta foto
} else { # anterior foto:
ffal = c(ffal,"E") # foto y escudo: escudo
}
} else { # actual foto: F
if (img_ant) { # anterior escudo: E
ffal = c(ffal,"F") # escudo y foto: sí hay foto
} else { # anterior foto:
ffal = c(ffal,"E","F") # foto y foto: falta escudo
}
}
}
ifotos = which(!(ffal=="E"))
qfotos = ffal[ifotos]
sifotos = which(qfotos=="F")
# Paso 2c: extrae apellidos y nombre de los alumnos
text <- pdf_text(ficheropdf)
dat01 = c() # contiene apellidos y nombre
dat02 = c() # contiene apellidos y nombre separados por guiones
for (j in 1:length(text)) {
pagina = str_split(text[j],"\n")
lineas = unlist(pagina)
for (i in 1:length(lineas)) {
res = str_detect(lineas[i],"Apellidos, nombre")
if (res) {
ss = unlist(str_split(lineas[i],"Apellidos, nombre"))
ss1 = str_trim(ss[2])
dat01 = c(dat01,ss1)
dat02 = c(dat02,str_remove_all(str_replace_all(ss1," ","_"),","))
}
}
}
nb_sifotos = dat02[sifotos]
if (!dir.exists("fotos")) {
dir.create("fotos")
}
# Paso 3:
cadenafmt = paste0("fotos/",raiz_nombrefotos,"%02d_%s.png")
vsnombres = sprintf(cadenafmt,sifotos,nb_sifotos)
for (i in 1:length(vnombres)) {
fichero = image_read(vnombres[i])
fichero_png = image_convert(fichero,"png")
image_info(fichero_png)
image_write(fichero_png,path = vsnombres[i])
unlink(vnombres[i])
}
}Descarga del código R del proyecto
Nota
Para realizar esta tarea en su ordenador:
Descargar el fichero comprimido: extraerfotos_codigoR.zip.
Descomprimir el fichero.
Copiar el fichero “Ficha.pdf” en la carpeta del proyecto.
Con el software instalado para su sistema operativo, ejecutar el código R como se señaló anteriormente.
Galería de imágenes:
sessionInfo()R version 4.1.1 (2021-08-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
loaded via a namespace (and not attached):
[1] digest_0.6.29 jsonlite_1.8.0 magrittr_2.0.3 evaluate_0.15
[5] blogdown_1.10 rlang_1.0.2 stringi_1.7.6 cli_3.3.0
[9] rstudioapi_0.13 rmarkdown_2.14 tools_4.1.1 stringr_1.4.0
[13] htmlwidgets_1.5.4 xfun_0.31 yaml_2.3.5 fastmap_1.1.0
[17] compiler_4.1.1 htmltools_0.5.2 knitr_1.39 Referencias
Ooms, Jeroen. 2018a. magick: Advanced Graphics and Image-Processing in R. https://CRAN.R-project.org/package=magick.
———. 2018b. pdftools: Text Extraction, Rendering and Converting of PDF Documents. https://CRAN.R-project.org/package=pdftools.
Wickham, Hadley. 2018. stringr: Simple, Consistent Wrappers for Common String Operations. https://CRAN.R-project.org/package=stringr.
Xie, Yihui, Alison Presmanes Hill, y Amber Thomas. 2017. blogdown: Creating Websites with R Markdown. Boca Raton, Florida: Chapman; Hall/CRC. https://github.com/rstudio/blogdown.